Locating domains
If you have a sequence of more than about 500 amino acids, you can be nearly certain that it will
be divided into discrete functional domains. If possible, it is preferable to split such large
proteins up and consider each domain separately. You can predict the locatation of domains in a
few different ways. The methods below are given (approximately) from most to least confident.
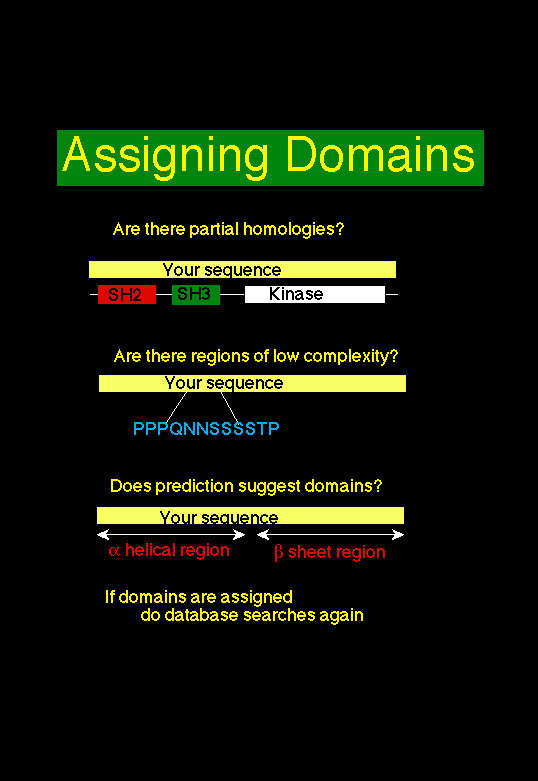
- If homology to other sequences occurs only over a portion of the probe sequence and the other
sequences are whole (i.e. not partial sequences), then this provides the strongest evidence for domain
structure.
You can either do database searches yourself or make use of well-curated, pre-defined databases of
protein domains. Searches of these databases (see links below) will often
assign domains easily.
- SMART (Oxford/EMBL)
- PFAM (Sanger Centre/Wash-U/Karolinska Intitutet)
- COGS (NCBI)
- PRINTS (UCL/Manchester)
- BLOCKS (Fred Hutchinson Cancer Research Centre, Seatle)
- SBASE (ICGEB, Trieste)
You can also find domain descriptions in the annotations in
SWISSPROT.
- Regions of low-complexity often separate domains in multidomain proteins. Long stretches of
repeated residues, particularly Proline, Glutamine, Serine or Threonine often indicate linker sequences
and are usually a good place to split proteins into domains.
Low complexity regions can be defined using the program
SEG which is generally
available in most BLAST distributions or web servers
(a version of SEG is also contained within the GCG suite of programs).
- Transmembrane segments are also very good dividing points, since they can easily separate
extracellular from intracellular domains. There are many methods for predicting these segments, including:
- Something else to consider are the presence of coiled-coils.
These unusual structural features sometimes (but not always) indicate
where proteins can be divided into domains. You can predict coiled coils
at the COILS server or you can
download the COILS program (recently re-written by me of all people; a version of SEG is also contained within the GCG suite of programs).
- Secondary structure prediction methods (see below) will often predict regions of proteins to have
different protein structural classes. For example one region of sequence may be predicted to contain
only lpha helices and another to contain only beta sheets. These can often, though not always, suggest
likely domain structure (e.g. an all alpha domain and an all beta domain)
If you have separated a sequence into domains, then it is very important to repeat all the database
searches and alignments using the domains separately. Searches with sequences containing several
domains may not find all sub-homologies, particularly if the domains are abundent in the database
(e.g. kinases, SH2 domains, etc.). There may also be "hidden" domains.
For example if there is a stretch of 80 amino acids with few homologues
nested in between a kinase and an SH2 domain, then you may miss matches
found when searching the whole sequence against a database.
Anyway, here is my slide from the talk related to this subject:
Back to the Flowchart